





























In deep learning, the vanishing gradient problem is a common issue that can hinder the performance and training of neural networks. It’s one of the biggest hurdles that machine learning engineers face, especially when working with deep networks. If you’ve ever wondered why your neural network isn’t training as expected, the vanishing gradient problem might be the culprit.
This article will explore the vanishing gradient problem, why it happens, and how it impacts neural networks. We’ll also cover some ways to mitigate this issue so you can keep your models performing at their best. By the end, you’ll have a solid understanding of the topic, ensuring you’re prepared to tackle this challenge head-on.
What is the Vanishing Gradient Problem?
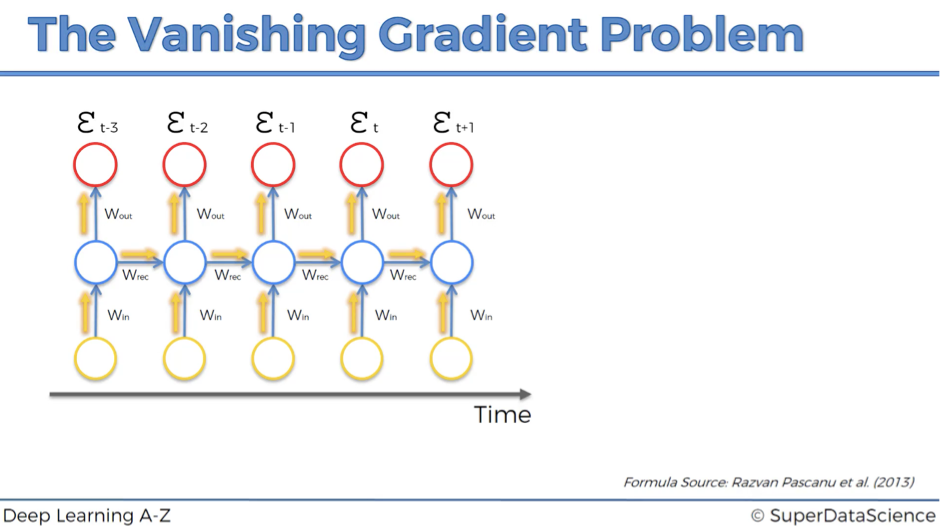
At its core, the vanishing gradient problem occurs during the backpropagation process in deep neural networks. Backpropagation is a technique used to train these networks by adjusting the weights of neurons based on the gradient of the loss function. This gradient represents how much the model’s output changes concerning its weights. Ideally, you want these gradients to be large enough for meaningful weight updates during training.
However, in deep networks, as the gradients are propagated backward through multiple layers, they often shrink exponentially. By reaching the earlier layers, the gradients become so small that they have little to no impact on the weight updates. This is called the vanishing gradient problem, and it prevents the model from learning effectively.
Symptoms of the Vanishing Gradient Problem
How do you know if your model suffers from the vanishing gradient problem? Here are a few signs to look out for:
- The network takes an unusually long time to train.
- The loss function decreases very slowly or plateaus after a few epochs.
- Earlier network layers learn slowly or not at all, while the last layers update normally.
If you notice these symptoms, you’re likely encountering the vanishing gradient problem.
Why Does the Vanishing Gradient Problem Occur?
Understanding why the vanishing gradient problem happens is crucial in finding solutions to overcome it.
Activation Functions and the Role They Play
The main cause of the vanishing gradient problem is the choice of activation function. Many traditional neural networks use activation functions like the sigmoid or tanh functions. These functions have gradients that decrease significantly as the input moves away from zero. As a result, when these activation functions are used in deep networks, the gradients can diminish as they propagate backward through the layers, leading to the vanishing gradient problem.
- Sigmoid Function: This activation function compresses its input to a range between 0 and 1. While this is useful in certain scenarios, the gradient of the sigmoid function becomes very small for inputs that are much larger or smaller than zero.
- Tanh Function: The tanh activation function compresses its input to a range between -1 and 1, which helps center the data. However, similar to the sigmoid function, the gradient of tanh also decreases for inputs far from zero.
Deep Networks and Backpropagation
The depth of a neural network exacerbates the vanishing gradient problem. As backpropagation moves through each layer, the gradients get multiplied by the weights and derivatives of the activation functions. This repeated multiplication in deep networks with many layers causes the gradients to shrink exponentially.
This means that the weight updates become smaller and smaller in the earlier layers of the network. Eventually, the earlier layers stop learning, while the later layers, which are closer to the output, update normally.
How the Vanishing Gradient Problem Impacts Neural Networks
The vanishing gradient problem has a significant impact on the ability of neural networks to learn. It can cause a variety of issues, including:
- Slow Learning: When the gradients vanish, the model learns very slowly. The loss function can take a long time to decrease, resulting in inefficient training.
- Difficulty in Training Deep Networks: The deeper the network, the more layers the vanishing gradient problem affects. This makes it difficult to train deep networks and extract meaningful features from the data.
- Poor Performance in Earlier Layers: As the gradients diminish in earlier layers, these layers stop learning. Since earlier layers capture basic features like edges or shapes in images, this can severely affect the model’s performance.
A Simple Table: Symptoms and Impact
SymptomImpact on Neural Networks
Slow training progress Inefficient learning and extended training times
Loss function plateaus Stuck at a suboptimal solution
Earlier layers stop learning Poor feature extraction and performance
Techniques to Mitigate the Vanishing Gradient Problem
Thankfully, several strategies have emerged over the years to combat the vanishing gradient problem. Below are some of the most commonly used methods.
- ReLU Activation Function
One of the most effective ways to mitigate the vanishing gradient problem is to replace the traditional activation functions with the Rectified Linear Unit (ReLU). The ReLU function allows for non-linear transformations while avoiding vanishing gradients.
- ReLU: Unlike sigmoid and tanh, the ReLU activation function does not compress its input into a small range. Instead, it returns the input value if positive and zero otherwise. This helps maintain larger gradients during backpropagation, allowing earlier layers to continue learning.
Several ReLU variants, such as Leaky ReLU and Parametric ReLU, address the problem of neurons “dying” when they output zero for a long time.
- Weight Initialization Techniques
Proper weight initialization can also help address the vanishing gradient problem. In deep networks, if the weights are too small or too large, they can exacerbate the shrinking gradients during backpropagation.
- Xavier Initialization: This method initializes weights to a small value dependent on the network size. It helps maintain stable gradients, preventing them from vanishing.
- He Initialization: This technique is especially effective when using ReLU activation functions. It ensures that the weights are initialized to a value that prevents the gradients from shrinking too quickly.
- Batch Normalization
Batch normalization is another technique that can mitigate the vanishing gradient problem. It normalizes the input to each layer by scaling and shifting the data to have a mean of zero and a standard deviation of one. This helps maintain more stable gradients throughout the network, making it easier to train deep models.
- Gradient Clipping
Sometimes, clipping the gradients during backpropagation can prevent them from vanishing entirely. Gradient clipping ensures that the gradients remain within a certain range, preventing them from becoming too small (or too large) to be useful.
- Skip Connections (Residual Networks)
Skip connections, used in architectures like ResNet, allow gradients to bypass certain layers, ensuring they don’t vanish as they move backward. These connections effectively “skip” over layers, allowing the model to retain the gradients and continue learning.
Why Solving the Vanishing Gradient Problem Matters
Understanding and addressing the vanishing gradient problem is crucial for advancing deep learning. As neural networks become deeper and more complex, solving this issue becomes more important to ensure models can learn effectively and efficiently.
- Improves Training Efficiency: Solving the vanishing gradient problem speeds up the training process and allows models to converge more quickly.
- Enables Deeper Networks: By mitigating the vanishing gradient problem, training deeper networks that can learn more complex patterns and features becomes feasible.
- Enhances Model Performance: Models that can fully utilize all layers, including the earlier ones, often perform better. These layers capture basic patterns that are crucial for accurate predictions.
Conclusion: Moving Forward with Deep Learning
The vanishing gradient problem is one of the key challenges in deep learning, particularly when training deep neural networks. While it can be frustrating, understanding why it happens and how to address it is essential for anyone working in machine learning.
With strategies like ReLU activation functions, proper weight initialization, and batch normalization, the effects of the vanishing gradient problem can be mitigated. These techniques make it easier to train deeper networks, improving your models’ speed and performance.
So, the next time you encounter slow training or stalled learning in your neural networks, remember that the vanishing gradient problem could be to blame. But with the right tools and techniques, it’s a challenge that can be overcome, paving the way for more powerful and efficient models in deep learning.
By mastering the solutions to the vanishing gradient problem, you’ll enhance your technical skills and contribute to the ongoing progress in artificial intelligence. The future of AI is full of potential, and understanding this issue is just one step in unlocking that potential.



