





























Deep learning has made significant strides in recent years in the ever-evolving world of artificial intelligence (AI). One of the most groundbreaking developments in this field is ResNet architecture. Standing for Residual Network, ResNet has become a crucial building block in designing deep learning models, particularly those that tackle image classification and computer vision tasks. So, what makes ResNet architecture unique, and why has it gained such widespread adoption? Let’s dive into the world of ResNet and understand how it’s shaping the future of AI.
What is ResNet Architecture?
ResNet architecture refers to a specific type of artificial neural network that allows for constructing intense networks by mitigating the vanishing gradient problem. Traditional neural networks face difficulties when layers increase beyond a certain point, as gradients start to diminish, making training inefficient. ResNet architecture, introduced by Kaiming He and colleagues in 2015, solves this by introducing shortcut connections, enabling the model to learn residual functions instead of trying to understand the entire mapping function.
At its core, ResNet architecture includes:
- Shortcut connections that bypass one or more layers.
- Residual learning models only the “difference” between input and output rather than a complete transformation.
- The ability to build deep networks, such as ResNet-50, ResNet-101, and ResNet-152, without significant performance degradation.
Why Is ResNet Architecture Important?
In deep learning, deeper networks generally provide better performance. However, increasing depth also brings challenges such as:
- Vanishing gradients: As layers increase, gradients become too small, leading to poor learning during training.
- Exploding gradients: Alternatively, gradients can grow exponentially large, causing instability in training.
- Overfitting: Complex models may fit the training data too well but perform poorly on unseen data.
ResNet architecture addresses these issues by enabling deeper networks to be trained without the adverse effects of vanishing or exploding gradients. This makes it possible to design models with hundreds or even thousands of layers that can be trained efficiently, which was nearly impossible before the introduction of ResNet.
How Does ResNet Architecture Work?
The key to ResNet architecture lies in its residual learning framework. Instead of trying to learn an entire mapping from input to output, ResNet models focus on learning residuals — the difference between the input and output. This is achieved by using identity shortcut connections, which bypass layers and add the input directly to the output. By doing so, the model doesn’t need to learn the complete transformation; it only needs to know the part different from the identity.
Here’s how it works in simple terms:
- Traditional neural networks attempt to map the input xxx to some output H(x)H(x)H(x).
- ResNet architecture instead models the difference: F(x)=H(x)−xF(x) = H(x) – xF(x)=H(x)−x, which is called the residual.
- The network’s goal becomes learning F(x)F(x)F(x), and the final output is obtained by adding the input xxx back: H(x)=F(x)+xH(x) = F(x) + xH(x)=F(x)+x.
This approach allows ResNet to overcome the vanishing gradient problem by ensuring that gradients flow more quickly through the network.
Critical Components of ResNet Architecture:
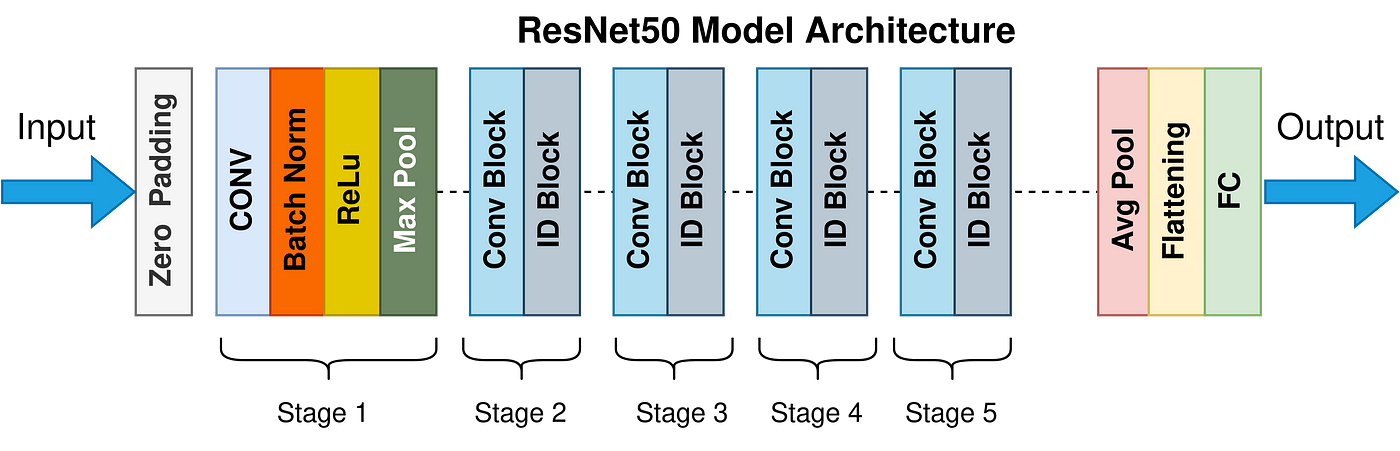
- Residual Blocks: These are ResNet’s core building blocks. Each block consists of layers with a shortcut connection that bypasses one or more layers. The output of these layers is then added to the original input.
- Bottleneck Design: In deeper versions of ResNet, such as ResNet-50 and beyond, a bottleneck design reduces the number of parameters and computations. The bottleneck consists of three layers (1×1, 3×3, and 1×1 convolutions) instead of two.
- Batch Normalization: This technique is used throughout the network to stabilize and speed up the training process by normalizing the output of each layer.
Benefits of ResNet Architecture
The success of ResNet architecture in deep learning applications comes from its unique advantages:
- Improved Training Efficiency: By addressing the vanishing gradient problem, ResNet allows for much deeper training of networks without losing performance.
- Higher Accuracy: ResNet models perform state-of-the-art tasks like image classification, object detection, and segmentation. It significantly outperforms older architectures like VGG and AlexNet.
- Versatility: ResNet can quickly adapt to various tasks and domains, including image recognition, natural language processing, and medical imaging.
- Modular Design: ResNet architecture is built with residual blocks, which makes it highly modular and scalable. By adding or removing blocks, you can easily adjust the depth of the network.
ResNet Variants: ResNet-50, ResNet-101, and Beyond
ResNet architecture comes in several variations, each designed for different use cases. The number following “ResNet” denotes the number of layers in the network:
- ResNet-50: Contains 50 layers and is widely used for image classification tasks due to its balance of accuracy and computational efficiency.
- ResNet-101: A more profound version with 101 layers, offering even better performance but requiring more computational resources.
- ResNet-152: One of the deepest networks in the ResNet family, with 152 layers, designed for highly complex tasks like object detection and segmentation.
Each variant maintains the core principle of residual learning, but the network can model more intricate data patterns with increasing layers.
ResNet VariantNumber of LayersUse Case
ResNet-50 50 Image classification, moderate complexity
ResNet-101 101 Advanced image classification, object detection
ResNet-152 152 Highly complex tasks, high accuracy needed
Applications of ResNet Architecture
The power and flexibility of ResNet architecture make it a go-to choice for many AI applications. Let’s explore some key areas where ResNet has made a substantial impact:
- Image Classification
ResNet models are widely used for image classification tasks, such as identifying objects within an image. They have been instrumental in winning several competitions, including the ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
- Object Detection
In object detection, ResNet is a backbone for models like Faster R-CNN and Mask R-CNN, which detect and classify objects within an image. ResNet’s depth allows these models to identify multiple objects, even in complex scenes accurately.
- Medical Imaging
ResNet models are also extensively used in medical imaging. They help diagnose diseases like cancer by analyzing medical images such as X-rays and MRIs. The depth of ResNet allows for more detailed feature extraction, leading to higher diagnostic accuracy.
- Natural Language Processing (NLP)
While ResNet is primarily known for its success in computer vision tasks, its principles are also applied in NLP models. Residual connections in transformer-based models help in processing long sequences of text efficiently.
Challenges and Limitations of ResNet Architecture
While ResNet architecture has made significant breakthroughs in deep learning, it’s not without its challenges:
- Computational Complexity: As ResNet models become more profound, they require more computational power and memory, making them difficult to deploy on devices with limited resources.
- Diminishing Returns: Although deeper networks generally perform better, the improvement becomes marginal after a certain point. For instance, the jump from ResNet-50 to ResNet-101 may only sometimes justify the additional computational cost.
- Overfitting: If not carefully managed, deeper networks like ResNet can still overfit the training data, especially when the dataset is small or lacks diversity.
Despite these challenges, ResNet remains a powerful tool in the deep learning toolkit, pushing the boundaries of AI capabilities.
The Future of ResNet Architecture
As we move forward in the era of deep learning, ResNet architecture will likely continue to evolve. Researchers are already working on hybrid models that combine the best aspects of ResNet with newer innovations like transformer models. This could lead to even more powerful and efficient AI systems capable of tackling a broader range of tasks.
In addition, the trend toward energy-efficient and lightweight models might lead to new ResNet versions optimized for deployment on mobile devices and edge computing platforms.
Conclusion
ResNet architecture has proven itself to be a game-changer in the world of AI and deep learning. By overcoming the limitations of traditional deep networks, ResNet enables researchers and engineers to build deeper, more accurate, and more versatile models. Whether it’s image classification, object detection, or medical imaging, ResNet architecture continues to push the frontiers of what’s possible in machine learning.
With ongoing advancements and research, ResNet’s future looks bright. It remains one of the most trusted and widely used architectures in the AI landscape. Its innovative design and scalability make it an indispensable tool for anyone looking to explore the cutting-edge of deep learning.



